Corca Medium 아카이브
코르카 신입 엔지니어를 위한 커리큘럼. 코르카 테크 팀의 신입 엔지니어 커리큘럼을 소개합니다.
새로운 회사에 입사한 첫 날에는 설렘 반, 긴장 반으로 출근하고는 합니다.
코르카의 첫날은 ‘오르카봇’을 맞이하며 시작됩니다. 신규 입사자는 오르카봇의 퀘스트를 진행하면서 자연 스럽게 회사의 모든 멤버와 소통하고 새로운 환경에 적응하게 됩니다.
오르카봇으로 코르카의 환경, 문화를 익힌다면 그 후 이어지는 본격적인 직무 관련 온보딩 과정을 통해 업무 에 적응하는 시간을 갖습니다.
‘오르카봇’에 대한 소개는 아래에서 확인하세요!
Hello 코르카, Hello 오르카봇

코르카 온보딩봇, 오르카봇을 소개합니다
medium.com 오늘은 코르카 테크 팀의 커리큘럼 2개를 소개합니다.
코르카에는 MLOps 엔지니어와 Data 엔지니어를 위해 각각 MLOps Curriculum, Data Curriculum이 준비되 어 있습니다.
(이 커리큘럼은 신입을 대상으로 만들어진 것이며 경력직에게는 해당되지 않습니다.)
MLOps Curriculum
MLOps와 DevOps는 실제 서비스에 ML모델을 배포하고 관리할 때 발생하는 문제를 다루는 분야로서, 현업 이 아닌 곳에서는 쉽게 접하기 어렵습니다.
그렇기에 일반적으로 간단한 개발 경험과 배포 경험 정도를 갖고 입사하게 되는 신입 엔지니어 분들의 경우, 달 가량의 커리큘럼을 진행 2 하고 있습니다.
또한 MLOps의 분야 특성상, 필요 시 타 분야의 엔지니어들도 MLOps 역량 강화를 위해 MLOps Curriculum 을 진행할 수 있습니다.
의 목표 MLOps Curriculum 는 3가지입니다.
REST API와 데이터베이스 등 전반적인 백엔드 개발 지식을 습득합니다.
DevOps의 철학을 이해하고 그 철학을 이루기 위한 기능을 적용합니다.
DevOps의 개념에서 더 나아가 MLOps에서 필요한 기능을 이해합니다.
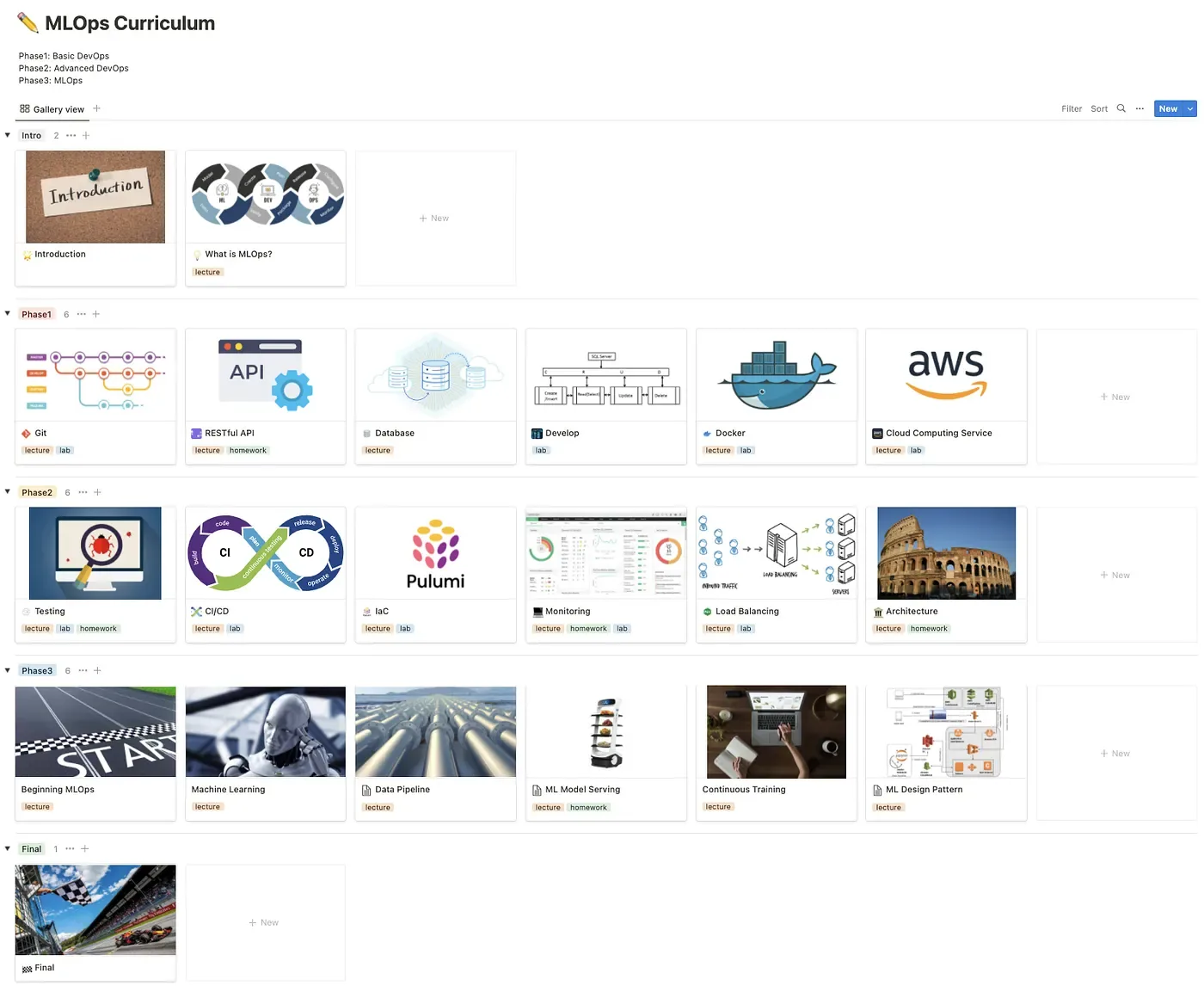
개의 MLOps Curriculum은 총 3 Phase로 나눠집니다.
첫번째 Phase에서는 기본적인 개발 태스크 6개, 두번째 Phase에서는 DevOps를 실제로 적용해보는 태스크 6개, 세번째 Phase에서는 MLOps를 이해하는 태스크 6개로 구성되어 있습니다.
아래는 실제 커리큘럼의 모습입니다.
Phase 1.
Phase 1에서 다루는 태스크는 Git, RESTful API, Database, Develop, Docker, Cloud Computing Service입니 다.
이러한 기본적인 태스크들을 커리큘럼 초반에 포함한 이유는 두 가지입니다.
첫번째로 , 이 태스크들은 엔지니어 업무의 기초가 되는만큼 이들을 정확하게 숙지하는 것이 중요합니다.
모호하게 알고있는 부분을 정확하게 재정비하고 모르고 있었던 부분을 명확히 파악하는 것이 목적입니다.
두번째로 , 코르카의 기술적인 문화에 쉽게 적응하기 위함입니다.
Git은 모든 회사에서 사용하는 시스템이지만 이를 사용하는 방법은 회사마다 다 다릅니다. 그 외에도 시스템 을 개발할 때 API를 어떻게 설계하는지, 어떻게 명세하는지, 도커를 어떻게 활용하는지, Cloud Computing Service를 어떻게 사용하는지 등 코르카만의 문화가 다수 존재합니다.
Phase 1은 개발 및 운영에 있어 가장 기초적이고 핵심적인 부분들로 구성되었습니다.
Task
팀으로써생산성을극대화하기위해서는어떻게해야할까
Git: ?
Lecture: 코르카의 git convention 파악, code review process 확인, 브랜칭 전략 습득
Assignment: 본인 레포 생성 후 PR 생성 효율적인통신을위해서어떤약속을미리해두면좋을까
RESTful API: ?
데이터를어떻게저장하고어떻게추출하는것이효율적일까
Database: ?
어떻게객체지향개발을할수있을까
Develop: ?
Assignment: 예시 API 개발 개발한서비스의환경을통일시킬수없을까
Docker: ?
Assignment: API서버 패키징 다른사람들도내가개발한서비스를사용하려면 Phase 2.
Phase 2에서 다루는 태스크는 Testing, CI/CD, IaC, Monitoring, Load Balancing, Architecture입니다.
개발과 운영을 자연스럽게 통합하면서 운영 DevOps의 정의가 사람마다 다르지만, 코르카에서는 DevOps를 ‘ 을 쉽게 만들어주는 모든 문화 방식 도구 , , ’로 정의합니다.
이에 따라 Phase 2에서는 단순히 태스크들을 해결하는 것 이상으로, Phase 1에서 경험한 운영을 토대로 스스 로 허점을 파악하고 해결해나갈 수 있도록 유도하고 있습니다.
운영상의 어려움을 직접 느끼고 그것을 극복하고자 새로운 태스크를 진행하게 됨으로써, 단순히 DevOps를 공부만 하는 것에 그치지 않고 본인의 경험을 토대로 자체적인 해결책을 진행하며 그 목적을 온전히 이해할 수 있게 됩니다.
태스크의 순서는 실제 프로젝트 환경과 유사하게 서비스의 크기가 커지면서 어려움을 느끼는 과정에 기반해 구성되었습니다.
Task
내가개발한기능이프로덕션에서에러를내면어떡하지 서비스이용자수를감당하지못하면어떡
Testing: ?
하지 ?
프로덕션에올리기전에테스트매번하는것이너무번거롭다 매번 로직접배포하는것이 번거롭다 이것을자동화할수는없을까 . ?
인프라를추가하거나변경할때모두개별적으로직접진행해야한다 인프라자체를재사용하면서쉽 IaC: .
게변경이가능하게할수는없을까 ?
새로배포한서비스의에러발생여부를어떻게쉽게파악할수있을까
Monitoring: ?
Lecture: Logging, Monitoring, Alerting, 타회사 장애 탐지 및 대응 프로세스 Assignment: 기능적인 에러와 비기능적인 에러에 대해 슬랙 알람 기능 구현 기능적인에러는코드레벨에서해결하면되지만 비기능적인에러는어떻게해결해야할
Load Balancing: ,
까 트래픽과부하 ? (e.g. ) Assignment: ECS auto scaling 설정 후 performance test로 동작 여부 확인 서비스규모가과하게커져서너무큰책임을지게된경우 이를어떻게효과적으로분리할수
Architecture: ,
있을까 ?
Assignment: 샘플 프로젝트 아키텍처 설계 Phase 3.
Phase 3에서 다루는 태스크는 Beginning MLOps, Machine Learning, Data Pipeline, ML Model Serving, Continuous Training, ML Design Pattern입니다.
가 무엇인지 그리고 모델 운영에 무엇이 필요한지 이 단계에서는 MLOps , ML 이해하게 됩니다.
실제 코르카에서 ML모델을 서빙할 때 갖춰야 할 지식 위주로 구성되어 있으며, 이는 지난 블로그 글에서 소 개드린 ‘BEAT’를 구현하기 위해 필요한 요소이기도 합니다.
기본적인 개발 지식 운영에 대한 지식 운영을 쉽게 만들어주는 다양한 도구 MLOps Curriculum을 마치면 , , 들 에 대한 이해 , MLOps 를 갖추게 되며 새로운 문제 상황에 직면하더라도 사전에 익힌 지식과 경험들을 기반 으로 헤쳐나갈 수 있게 됩니다.
MLOps Curriculum 소개를 마무리를 하면서 이를 훌륭하게 완수해준 첫번째 엔지니어의 레포를 소개합니 다.
MLOps Engineer at Corca. ECS endpoint : 3.38.172.73:3000 Phase 1의 구성은 크게 MLOps의 정 github.com
Data Curriculum
데이터 엔지니어링 업무의 기반을 Data Curriculum은 코르카의 신규 데이터 엔지니어들이 보다 효과적으로 이해 직접 실습 하고, 나아가 까지 해볼 수 있도록 설계되었습니다.
Data Curriculum은 7개의 섹션으로 나뉘어져 있으며, 각 섹션에는 태스크와 프로젝트가 있습니다.

- Introduction: 데이터 커리큘럼과 데이터 엔지니어링을 소개합니다.
- Common: 코르카의 엔지니어로서 알아야하는 공통적인 부분을 배웁니다.
- Retrieval: 데이터베이스에서 데이터를 조회하고, 이를 사용하는 방법을 배웁니다.
- Storage: 데이터베이스에 데이터를 효율적으로 저장하는 방법을 배웁니다.
- Data Flow: 데이터가 필요한 곳에 알맞은 형태로 가공하여 전달하는 방법을 배웁니다.
- Data Infra: 데이터가 필요한 사용자가 쉽게 데이터를 사용할 수 있는 환경에 대해 배웁니다.
- Endgame: 이전 섹션에서 배웠던 것들을 토대로 진행하는 마지막 프로젝트입니다.

데이터의 조회 저장 가공 인프라 개의 섹션 Phase 단위로 구성되어 있던 MLOps Curriculum와는 다르게, / / / 4 을 포함한 총 개의 섹션 7 으로 구성되어 있는 것이 핵심입니다.
또한, Data Curriculum에서는 태스크별 과제가 아닌 섹션 단위별 통합 과제가 주어집니다. 이는 섹션별로 필 요한 지식이 다르고, 하나의 섹션 안에서도 통합적인 지식이 요구되는 데이터 엔지니어링의 특성을 고려해 설계한 커리큘럼 구조입니다.
Data Curriculum의 메인 섹션으로는 Retrieval, Storage, Data Flow, Data Infra가 있습니다.
Retrieval
데이터베이스에서 데이터를 조회하고 사용하는 방법
에 대해 배우는 섹션입니다.
데이터에 관한 기본 지식 데이터의 분석 및 시각화 첫번째 섹션인 만큼 과 를 다룹니다.
Lecture
Background & SQL: 데이터베이스의 기초, SQL 문법 등을 배웁니다.
Pandas: 데이터를 불러오고 그것을 가공하여 유의미한 인사이트를 추출하는 방법에 대해 배웁니다.
kaggle 노트북 필사를 통해 pandas와 더욱 친숙해질 수 있습니다.
Data Visualization: 코르카에서 활용하는 라이브러리인 plotly를 통해 data visualization 방법을 배웁니 다.
Assignment
H&M Project: 캐글의 H&M 대회 데이터를 이용하여 시각화를 진행합니다.
섹션 데이터베이스에서 필요한 데이터를 추출하고 데이터를 직접 다루면서 분석 Retrieval 을 끝내면 , 까지 할 수 있게 됩니다.
데이터를 이해하기 쉽게 시각화 또한, 해서 다른 사람들에게 데이터에 대해 설명할 수 있게 됩니다.
Storage
Retrieval 섹션에서 사용했던 데이터들은 어떻게 보관되어 있었을까요?
어떠한 방식으로 데이터가 생성되고 저장되었을까요?
데이터의 특성별로 가장 효율적인 저장 방법은 무엇일까요?
섹션 Storage 의 목적은 위 궁금증들을 해결하는 것입니다.
Lecture
Data Model: 데이터를 저장하는 방법들에 대해 배웁니다. (Relational, Analytical, Key-Value, Column- Database Design: RDBMS를 설계하는 방법을 다룹니다.
Assignment
Taxi Database: 뉴욕 택시 데이터를 다운받고 postgresql에 직접 저장 후 쿼리를 실행해봅니다.
Lecture
OLAP vs OLTP: OLAP와 OLTP의 차이에 대해 배웁니다.
Data Warehouse: Data Warehouse가 왜 필요한지, 다른 데이터 저장 방식과 무엇이 다른지 배웁니다.
Columnar Databases: 데이터를 빠르게 분석하기 위한 Columnar Database의 원리와 사용방법을 배웁니 다.
Assignment
Taxi Warehouse: 뉴욕 택시 데이터를 활용하여 GCP Bigquery로 Warehouse를 구축합니다.
데이터의 형식과 활용 방법에 따라 적합한 방법을 선택하여 저장 Storage 섹션을 마치면 할 수 있게 됩니다.
Data Flow
데이터를 저장하기 위해서는 우선 데이터가 쌓여야 합니다. 데이터를 어떻게 수집하고 가공하여 저장하게 되는 것일까요?
섹션 여러 데이터 소스로부터 데이터를 수집하고 가공하여 데이터 저장소로 저장하는 데이 Data Flow 에서는 터 파이프라인 에 대해 배웁니다.
Lecture
ETL: Extract, Transform, Load 프로세스의 기초를 다룹니다.
Workflow Management: 많은 수의 ETL을 DAG로 처리하기 위한 Airflow에 대해 배웁니다.
Data Pipeline: ETL을 포함하는 개념인 데이터 파이프라인의 기초를 다룹니다.
Assignment
Taxi Pipeline: Airflow를 통해 매시간마다 택시 데이터를 가공하도록 합니다.
Lecture
Distributed Systems: 빅데이터를 안정적으로 처리하기 위한 분산시스템입니다.
Batch Data Processing: 하둡, 스파크의 구조와 배치 데이터를 처리하는 방법에 대해 배웁니다.
Streaming Data Processing: 카프카로 실시간 스트림 데이터를 처리해봅니다.
Assignment
Bidding Data Processing: 실시간 경매 데이터를 처리하여 참여자의 남은 예산을 지속적으로 계산합니 다.
를 적절하게 가공하여 이해관계자에게 전달 Data Flow 섹션을 마치면 batch data, stream data 할 수 있게 되 고가용성 내결함성 등 안정적인 데이터 처리 고, , 에 대해서도 배우게 됩니다.
Data Infra
데이터 사이언티스트와 엔지니어가 모델을 만들고 프로덕션에 적용하는 일련의 과정이 쉽고 효율적으로 진행되도록 돕는 환경 을 뜻합니다.
데이터 엔지니어는 적절한 환경을 구축함으로써 사람들이 데이터를 손쉽게 접근하고 사용할 수 있게 해야 합니다.
대시보드와 제일 대표적인 Data Infra로는 Feature Store가 있으나, 이는 상당히 복잡하기에 커리큘럼에서는 실시간 분석 데이터베이스 를 다룹니다.
Lecture
Data Infrastructure: 데이터 인프라의 중요성과 예시를 이해합니다.
Real-time Analytics Database: 카프카와 드루이드를 연동하여 실시간 분석 데이터베이스를 구축해보고 다른 데이터베이스와의 차이점을 파악합니다.
Data Dashboard: 실시간 빅데이터를 시각화할 수 있는 슈퍼셋을 이해하고 간단한 실습을 진행합니다.
Assignment
Budget Dashboard: Bidding Data Processing 태스크에서 계산한 예산을 슈퍼셋으로 실시간 확인 가능한 대시보드를 개발합니다.
배치 실시간 데이터를 수집하고 가공 데이터 활용 방법에 따라 여기까지 모든 섹션을 마치게 되면 / 할 수 있고, 효율적인 저장소를 구축 데이터를 분석하고 시각화하여 인사이트를 도출 할 수 있으며, 할 수 있게 됩니다. 그 머신러닝모델학습 실시간피처생성및저장 비즈니스의사결정을위한시각화 과정 속에서 , , 등 많은 것들 을 같이 이룰 수 있게 됩니다.
이 커리큘럼을 마치면 코르카의 데이터 엔지니어로서 방대한 규모의 데이터를 다룰 수 있게 됩니다.
코르카의 커리큘럼을 통해 쌓은 탄탄한 기초와 내공을 기반으로 지속적인 발전을 성취하고 앞으로의 문제들 을 해결할 수 있을 것입니다.
신입엔지니어가업무에잘적응할수있도록돕는것 코르카에서는 을 중요하게 생각하기 때문에 커리큘럼 을 지속적으로 업데이트하고 있습니다.
성공적으로 커리큘럼을 마친 엔지니어들은 다방면으로 업무에 기여하며 성장해왔고 지금도 성장해나가고 있습니다.
지금까지 MLOps Curriculum, Data Curriculum에 대한 간단한 소개였습니다.
우리가 살아가는 세상을 AI 기술로 변화시키는 팀 Corca는 고도화된 기술력과 기획력을 토대로 새로운 가치 를 창출하고 있습니다.
Corca의 여정에 함께하실 분들은 코르카 채용페이지를 확인해주세요!
기술 발전의 혜택을 모두가 누리게 하여 인류 문명의 발전에 기여하는 코르카