Corca Medium 아카이브
BEAT (Bidding Engine for AdTech) 아키텍처 (2편)
medium.com 지난 BEAT (Bidding Engine for AdTech) 아키텍처 (1편)에 이어 (2편)에서는 저희의 니즈에 맞는 아키텍처를 설계할 수 있도록 고민한 측면에 대해 소개하고자 합니다.
의존성관리 변동성이높은컴포넌트 들의자유로운변경

내결함성 장애의발생가능성을인지하고장애확장을방지하는안정성
- :
확장성 트래픽의확장에맞춘자유로운인프라확장
- :
- 의존성 관리 (Dependency)
컴포넌트 의 이번 챕터에서는 서비스 운영과 유지보수의 효율성을 높이고, 배포의 난이도를 낮춰줄 수 있는 존성 관리 에 대해 알아보겠습니다.
의존성 관리는 코드 레벨만이 아니라 컴포넌트 레벨에서도 굉장히 중요합니다.
안정성의방향으로의존하라 의존성 관리의 기본 원칙은 “ ” 입니다.
모든 컴포넌트의 변동 가능성을 아키텍처 설계에 반영 컴포넌트는 항상 변경될 수 있기 때문에 해야 합니다.
만약 변동성이 작은 컴포넌트가 변동성이 큰 컴포넌트에 의존하게 된다면 어떻게 될까요?
코드 레벨 의 예시로는, Interface가 concrete class의 method 구현 디테일에 의존하는 상황이 있습니다.
이 경우 매번 Interface가 변할 것이며, 이는 매우 바람직하지 않습니다. Interface는 변동성이 적어야 하며, 가 에 의존하여 최소한의 변경만이 있어야 합니다
컴포넌트 레벨 에서도 동일하게, 낮은 변동성의 컴포넌트가 높은 변동성의 컴포넌트에 의존하게 되면 후자가 다방면의 수정 작업이 동시다발적으로 요구 변경될 때마다 됩니다.
컴포넌트 응집도를 극대화 그렇기 때문에 함으로써 컴포넌트 간의 의존성을 최소화
- 하고
높은 변동성의 컴포넌트가 낮은 변동성의 컴포넌트에 의존
- 하게 할 때
자유로운 컴포넌트 변경이 가능해질 것입니다.
지금까지 설명드린 컴포넌트 중 가장 자주 변경될 것 같은 컴포넌트는 무엇인가요?
또 변경이 제일 적을 것 같은 컴포넌트는 무엇인가요?
- Light Trainer
- Actuator
- Inference
- Receiver
- Data Stream
- Supervisor
정답은 1, 2번 / 6번(4, 5번도 정답)입니다.
와 반복적인 수정을 통해 계속 광고의 성과를 결정짓는 요소는 Actuator Light Trainer이며, 이 컴포넌트들은 성능을 향상 시켜야 합니다.
그어떤컴포넌트도이 개의컴포넌트에의존하지않도록설계 그렇기에 2 하였습니다.
다시 말해, Actuator, Light Trainer의 코드, 언어, 배포 방식이 바뀌더라도 다른 컴포넌트에는 전혀 영향을 미 치지 않습니다.
Actuator와 Light Trainer에 의존하는 컴포넌트는 없으니까요.
변동성이 낮은 반대로 가장 컴포넌트는 Supervisor입니다.
(Receiver, Data Stream도 비슷하게 변동성이 거의 없습니다.)
Supervisor는 state, checkpoint를 관리하고 Inference에 전달하는 역할을 하므로, 한번 제대로 개발된 이상, 로직이 변경될 가능성이 낮습니다.
위 그림을 자세히 보면 이전 글의 그림과 차이가 있는데요, 바로 화살표 방향입니다.
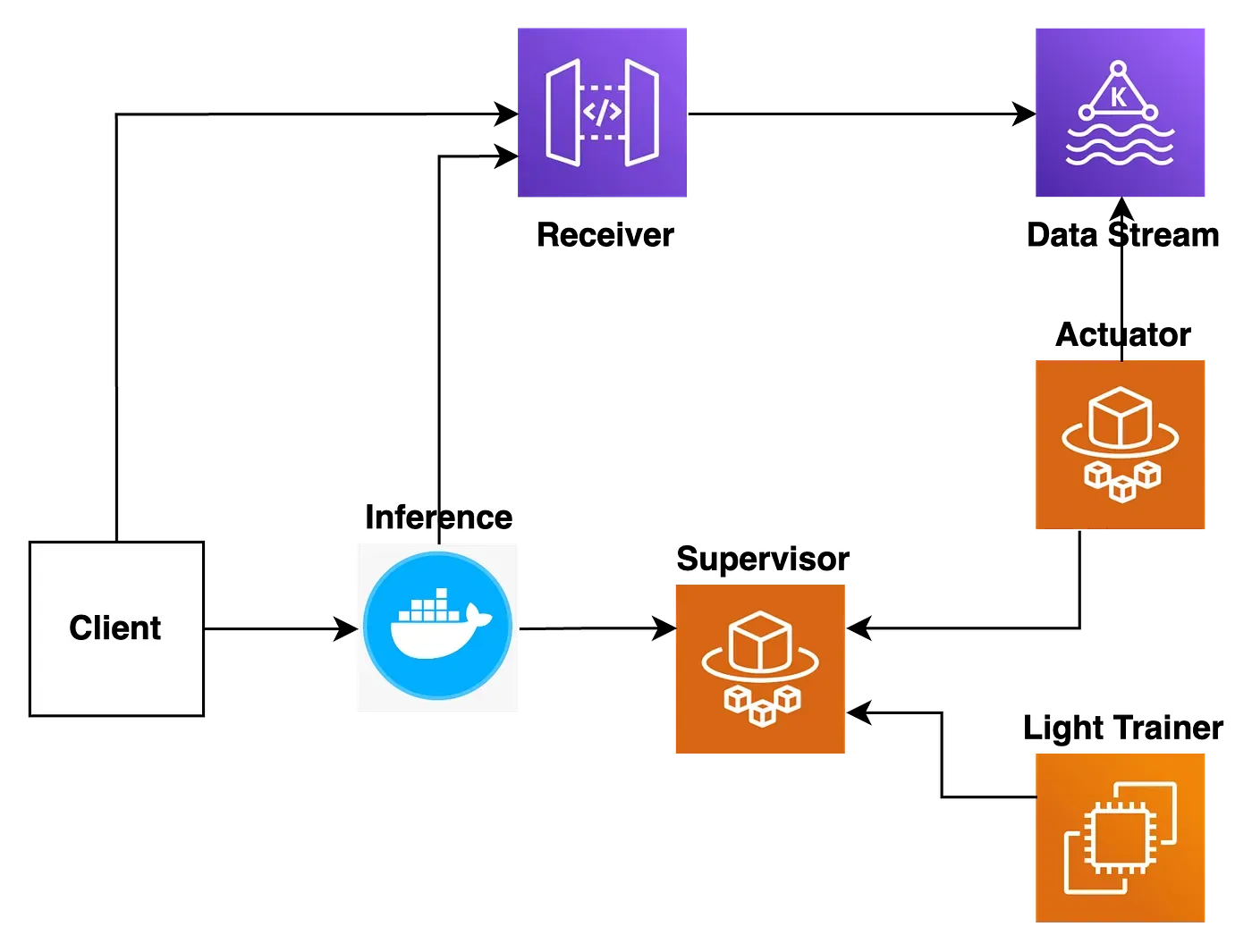
이전 그림에서는 데이터의 흐름을 화살표로 나타냈다면, 이 그림에서는 컴포넌트간 의존성을 화살표로 나타 내었습니다.
(A → B 이면 A 컴포넌트가 B 컴포넌트에 의존한다는 뜻입니다.)
변동성이 적은 Receiver, Data Stream, Supervisor는 Fan-in(들어오는 의존성)이 Fan-out(나가는 의존성)보 다 훨씬 더 많습니다.
안정적인 컴포넌트 이들은 전부 (stable) 입니다.
변동성이 큰 Actuator, Light Trainer의 경우, Fan-out이 Fan-in보다 많습니다. 사실, 아예 Fan-in이 존재하지 않습니다.
가장 불안정하고 변동성이 큰 개의 컴포넌트 이들은 BEAT에서 2 이기 때문이죠.
참고) ‘의존한다’의 의미를 풀어서 설명하면 다음과 같습니다.
현재 BEAT에서는 Actuator가 Data Stream의 주소를 갖고 있고, Data Stream이 준비해둔 데이터를 Actuator 가 가져옵니다.
Actuator가 Data Stream의 데이터를 사용하기 때문에, Data Stream이 변경되면 Actuator도 같이 변해야 합 니다.
이 경우 가 에 의존한다고 말합니다
이 에 의존 반대로 BEAT의 의존성 설계가 잘못되어 Data Stream Actuator 하게 된다면 어떻게 될까요?
Data Stream이 Actuator 주소 데이터를 바로 Actuator에게 전달합니다.
만약 Actuator에서 사용하는 데이터를 누락시킬 경우, Data Stream에서 Actuator에게 전달하는 데이터의 형 식이 맞지 않아 에러가 발생할 것입니다.
- 내결함성 (Fault Tolerance)
이번 챕터에서는 내결함성을 갖는 아키텍처를 만들기 위한 개발 철학, 배포 방식, LMA스택(Logging, Monitoring, Alerting), 리커버리 테스트까지 알아보겠습니다.
시스템의 일부 구성 요소가 작동을 멈춰도 전체 모델은 계속 작동할 수 있도록 유지하는 것 우리의 목표는 이 었습니다.
애드테크의 대규모 데이터와 인프라를 다루다보면, 아무리 완벽한 모델이라도 언제든 문제가 발생할 수 있 습니다.
네트워크 이슈로 메시지가 전달이 되지 않을 수도 있고, 지연이 생길 수도 있으며, 예기치 못한 이유로 서비 스가 중단될 수도 있습니다.
장애가발생해도모델이원활히작 그렇기 때문에 가장 중요한 것은 장애의 발생을 막는 것보다 중요한 것은 동하게하는것 이었습니다.
장애는 어디에서 발생할 수 있을까요?
서비스 중단 1.
아래와 같은 다양한 상황에서 서비스 중단이 발생할 수 있습니다.
개발 과정의 오류로 인한 로직 에러 발생 네트워크 지연으로 인한 초기화 실패 DB의 과부하로 인한 연결 오류 스팟 인스턴스 중지 재배포 마이크로서비스들 간의 연결 중단 송수신 메시지의 누락 또는 중첩
- /
항상 연결을 보장해주는 네트워크는 없으며, 주고받는 메시지들이 언제나 exactly-once로 전달된다는 보장 또한 없습니다.
메시지가 누락되거나 중첩되는 경우에도, 명확한 예외 처리를 통해 서비스 중단을 방지해야 합니다.
장애 대응을 위한 개발 및 배포 방식 가지 장애 코르카는 모든 컴포넌트들에 대해 이 2 를 다루는 것을 목표했습니다.
장애를 효과적으로 다룬다는 것은 무엇일까요?
현실적 예시로는 화재 상황과 비교할 수 있습니다.
화재는 우리 삶에 큰 피해를 줍니다. 그러나 이 세상 어디에도 화재를 100% 예방하지 못합니다. 다만 화재가 발생했을 때의 대처 과정에서의 차이는 존재합니다.
5분 내로 소방차가 도착해 화재를 진압하는 경우가 있는 반면, 1시간이 지나서도 소방차가 도착하지 않아 진 화에 어려움을 겪는 경우도 있습니다.
코르카는 화재가 발생하더라도 이를 신속하게 진압할 수 있도록, 일종의 소방 교육을 통해 개개인이 자체적 으로 진화 작업을 진행할 수 있도록 만들고자 했습니다.
다시 개발 세상으로 돌아오겠습니다.
우리의 목표는 다음과 같습니다.
컴포넌트 내에서 자체적으로 장애를 다루는 환경 1.
장애 발생 시 주변 컴포넌트로의 확산 방지 2.
장애 발생 시 개발자가 빠른 조치를 취할 수 있도록 전달
- alert
- 컴포넌트 내에서 자체적으로 장애를 다루는 환경
기본적으로 어떤 컴포넌트들은 언제든 중단될 수 있으며, 컴포넌트가 중단될 때마다 매번 재배포를 진행하 는 것은 비효율적입니다.
컴포넌트가 중단되더라도 다시 가동시킬 수 있는 서비스 그렇기에 를 사용하고자 했습니다.
의 AWS Elastic Container Service, ECS를 사용하면, 컨테이너가 몇 개 중단되더라도, 즉시 동일 개수의 컨테이 목표로설정한컨테이너의개수를항상유지 너가 되살아나며 할 수 있게 됩니다.
- 장애 발생 시 주변 컴포넌트로의 확산 방지
모든 컴포넌트는 최소 하나의 다른 컴포넌트와 의존 관계를 지닙니다.
그러나해당컴포넌트의생존여부와는절대의존성을가져서는안됩니다
.
Actuator에서 Supervisor로 state를 보낼 때 Supervisor가 죽어있다면 로그만 남기고 다음 일을 처리해야 합 니다. 그렇게 되면 ECS를 통해 Supervisor가 다시 살아나고 그 다음의 메시지를 원활히 전달받게 됩니다.
의모든컴포넌트간의연결은이러한 BEAT weak connection으로 구성되며, 개발 과정에 있어 이러한 부분의 예외처리는 특히 주의깊게 확인해야 할 부분입니다.
- 장애 발생 시 개발자가 빠른 조치를 취할 수 있도록 alert 전달
예기치 못한 크리티컬한 장애가 발생할 경우, 반드시 개발자에게 alerting을 즉각적으로 전달해야 합니다.
장애가 발생할 가능성이 높아졌을 때 장애가 발생했을 때 전달하면 개발자가 문제를 사전에 방지하는 데 도움이 됩니다.
자동적으로슬랙 가전달되도록 그렇기에 코르카는 모든 인프라에서 warning, error 기준을 설정하여 alert 개발 했고, 이를 통해 문제가 발생하더라도 개발자가 즉각적으로 해결할 수 있었습니다.
일반적으로 CPU utilization과 memory utilization 지표를 많이 쓰고 response time, bytes per second 등의 지표도 사용합니다.
메시지 처리에 관한 대처 방법
그 다음은 입니다.

와 사이의 연결 Inference Supervisor 은 추론부에 직접적인 영향을 주기 때문에 매우 자세히 예외처리를 하 였습니다.
그에 반해 다른 연결은 비교적 모델에 미치는 영향이 약했고, state나 checkpoint가 한번씩 전달이 되지 않더 방식으로 메시지를 처리 라도 다음 순서가 곧바로 전달되어 문제가 되지 않기 때문에 at-most-once 하였습니 다.
테스트 과정
이제 모델이 제대로 개발됐는지 확인하기 위한 이 필요합니다.
BEAT에서는 모든 컴포넌트마다 “Recovery Test”를 진행합니다.
모든컴포넌트를로컬에서띄운후 임의의컴포넌트를하나씩꺼보는방식 , 으로 진행됩니다.
모든 컴포넌트를 번갈아가면서 꺼보고, 전부 다시 켰을 때 아무런 문제 없이 모델이 돌아가면 Recovery Test 를 통과합니다.
만약 하나의 컴포넌트를 껐을 때 다른 컴포넌트에서 에러가 발생하면서 연쇄적으로 장애가 확산된다면, 개 발에 오류가 있는 것이라고 볼 수 있습니다.
- 확장성 (Scalability)
이번 챕터에서는 확장성이 있는 아키텍처를 만들기 위해 고려한 컴포넌트별 트래픽 양의 영향 정도, stateless한 컴포넌트, auto scaling까지 알아보겠습니다.
애드테크 프로젝트의 특성상, 트래픽의 양이 일정하지 않고 수시로 변동하기 때문에 어느 날 갑자기 트래픽 이 4–5배가 증가할 수도 있습니다.
인프라 레벨에서 트 갑자기 트래픽이 감소하면 인프라 비용 절약을 위해 인프라를 감소시킬 수 있어야 하고, 래픽의 변화에 자동 대응 하여 트래픽의 증가에도 인프라가 robust하게 버텨야 합니다.
스케일을 키우는 방법에는 scale-out, scale-up 2가지 방법이 있습니다.
scale-up: 기존의 서버를 보다 높은 사양으로 업그레이드 scale-out: 장비를 추가해서 확장하는 방식 IDC를 사용할 땐 2가지 방법 모두 쉽지 않지만, cloud service를 사용하면 두 가지 모두 적용 가능합니다.
은 성능 향상에 한계
다만 인스턴스 사양의 최대치는 정해져 있기에, scale-up 를 가져옵니다. 이런 이유로 코 성능 향상 이 가능하도록 설계 르카에서는 을 위해 scale-out 하였습니다.
scale-out이 가능한 컴포넌트를 만들 때에는 고려해야 할 사항들이 여러가지 있습니다.
가장 먼저 트래픽 양이 미치는 영향의 정도를 확인해봐야 합니다.
각 컴포넌트의 특성에 따라 어떤 경우에는 트래픽의 증가에 직격탄을 맞을 수도 있고, 다른 경우에는 아무 영 향을 받지 않을 수도 있습니다. 아무 영향을 받지 않는 컴포넌트는 scale-out 설계가 불필요합니다.
BEAT의 예시를 들어보겠습니다. (T는 traffic의 개수를 의미합니다.)
Actuator는 Data Stream에서 aggregate된 정보를 전달받기 때문에 트래픽의 양과 연관성이 낮습니다.
과 비례 다만 key 개수에는 영향을 받게 되는데, 대략적으로 log (# of Traffic) 한다고 가정합니다.
Light Trainer는 트래픽의 모든 데이터를 그대로 사용합니다. 데이터가 많아서 다운샘플링을 진행하지만, 비 트래픽과 비례 례해서 다운샘플링을 하므로 한다고 볼 수 있습니다.
- Inference: O(T)
트래픽과 비례 하나의 트래픽당 하나의 request에 응답해야 하므로 합니다.
- Receiver: O(T)
트래픽과 비례 모든 트래픽을 받아서 Data Stream으로 전달하기에 합니다.
트래픽과 비례 모든 트래픽을 aggregate하여 Actuator에 전달하므로 합니다.
- Supervisor: O(T)
Supervisor는 직접 트래픽을 다루지 않습니다. 그러나 Supervisor와 연결을 맺고 있는 Inference의 개수가 트래픽에 비례 트래픽에 비례하므로 Supervisor의 연산량 또한 합니다.
모든 컴포넌트를 이 가능하도록 개발 이렇게 코르카는 scale-out 하게 되었습니다.
갑작스럽게 트래픽이 배가 증가하더라도 인프라 비용을 더 지불하면 안정적으로 쉽지 않은 과정이었지만 10 , 감당 할 수 있게 되기에 엄청난 확장성을 가지게 되었습니다.
- Stateless
(여기에서 말하는 state는 Actuator가 Supervisor에게 전달하는 state와 다르며, 일반적인 서비스의 상태 정 보를 의미합니다.)
서버가 추가로 확장되더라도 확장된 서버가 즉시 정상적인 동작을 할 수 있어야 합니다. 여기서 정상적인 동 작이라는 것은, 기존 서버와 정확히 같은 일을 하는 것을 의미합니다.
이를 위해서는 기존 서버에 남는 state를 아예 삭제하거나, state를 전달받아야 합니다.
한 서비스는 이 불가능하며 이 가능하려면 해야 합니다
Stateless: Receiver는 state가 없고 Inference는 state를 Supervisor로부터 주입받아서 stateless합니다.
Stateful: Actuator, Supervisor, Light Trainer의 경우에는 state가 전부 있었기에 state를 어딘가에 저장 해야 합니다.
따라서 Actuator는 Supervisor에, Light Trainer는 master node에 저장하는 방식으로 해결하였습니다.
- Auto Scaling
앞에서 scale-out이 필요한 컴포넌트를 찾아 scale-out이 가능하도록 개발을 했습니다.
을 언제 어떻게 그렇다면 이제 scale-out 해야 할지 알아야 합니다.
AWS에는 자동으로 scale-out을 해주는 auto scaling이라는 기능이 있습니다.
EC2, ECS 모두 갖고 있으며 이 2개의 서비스에서 모두 auto scaling을 적용하고 있습니다.
을 할 기준 auto scaling을 설정할 때는 scale-out, scale-in 을 설정해야 합니다. 이론적으로 정해진 기준은 없 으며 보통 실험을 통해 기준을 설정합니다.
코르카에서는 CPU utilization을 기본으로 auto scaling을 설정하고, 서버의 부하 정도를 확인하면서 auto 를 설정 scaling policy 하였습니다.
Conclusion
정해진 예산 안에서 광고의 효율을 극대화하는 프로젝트 코르카는 를 풀고 있습니다. 이 프로젝트의 대표적 인 3가지 특징은 다음과 같습니다.
- 초당 만 개씩 쌓이는 데이터
- 24/7 돌아가는 서비스
- 매일매일 격변하는 세상
이 특징을 반영할 수 있도록 고려한 부분들에 추가로 일반적으로 아키텍처를 설계할 때 고려해야 되는 것들 을 하나로 정리하면 아래와 같습니다.
- 컴포넌트 응집도를 높이기 위한 아키텍처 설계
- 변동성이 높은 컴포넌트가 변동성이 낮은 컴포넌트를 의존하도록 하는 의존성 관리
- 장애 확장을 방지하는 안정적인 아키텍처
- 트래픽 양의 확장에 맞춘 자유로운 인프라 확장
코르카에서는 우선적으로 목표를 명확히 제시하고, 이를 풀어나가기 위해 알맞은 기술을 적용할 때 기술의 본질을 온전히 실현 가능하다고 생각합니다.
그렇기에 우리가 문제를 푸는 과정은 대부분 다음 단계를 통해 진행됩니다.
- 문제 정의
- 문제를 풀 수 있는 수단 조사
- 실험과 검증 과정을 통해 잠재적인 문제와 실질적인 효과를 체계적으로 확인
- 적용
이번 설계에도 위의 과정이 녹아들어 최종적인 BEAT 아키텍처가 탄생하게 되었습니다.
물론 이 외에도 고민했던 지점들이 굉장히 많습니다.
- supervisor가 inference에게 state와 checkpoint를 어떻게 전달해야 하는가?
- 왜 Stream Data를 처리할 때 Kafka를 선택하였는가?
win, bid call matching 을 어디에서 해야 하는가? (DB? pub/sub? etc.)
위 3가지를 고려하여 kafka kinesis rabbitmq sqs 등등 여러 후보 중 kafka 선택
- 복잡한 아키텍처 속에서 테스트는 어떻게 구조화하였는가?
환경: 리서치 환경, 개발 환경, 컨테이너 환경, 오프라인 프로덕션 환경, 온라인 프로덕션 환경 테스트 커버리지: 실험, 컴포넌트 유닛테스트, 컴포넌트 E2E 테스트, 통합테스트, E2E 비기능 테스트(신 뢰성, 복구, 스트레스), E2E 기능 테스트
- CI/CD 파이프라인 구축
모노레포 vs 멀티레포 중 모노레포를 선택한 이유
빌드, 테스트, 배포를 어떻게 자동화했는가?
nx, pulumi 란?
- AWS Resource 관리
어떤 서비스를 어떤 인프라를 사용하여 배포하였는가 트레이너가 학습하기 위해 필요한 빅데이터를 어디에 저장해야 하는가 (S3, EFS, EBS) Kafka의 security 설정 Logging, Monitoring, Alerting 기준을 어떻게 세우는가 어떤 모니터링 방식을 사용하였는가
각 토픽에 대해 개별적 포스팅을 작성할 수 있을 정도로 많은 고민들을 하였습니다.
지금까지 다룬 내용 외에도 제어 모델과 머신러닝 모델에 대한 수많은 고민의 흔적이 아키텍처에 담겨있으 며, 이 2개의 모델에 대해서는 더 많은 이야기가 남아있기 때문에 추후 포스팅으로 돌아오도록 하겠습니다.
우리가 살아가는 세상을 AI 기술로 변화시키는 팀 Corca는 고도화된 기술력과 기획력을 토대로 새로운 가치 를 창출하고 있습니다.
Corca의 여정에 함께하실 분들은 코르카 채용페이지를 확인해주세요!
기술 발전의 혜택을 모두가 누리게 하여 인류 문명의 발전에 기여하는 코르카