Corca Medium 아카이브
BEAT (Bidding Engine for AdTech) 아키텍처 (1편)
정해진 예산 안에서 광고의 효율을 극대화하는 애드테크의 수많은 분야 중 가장 첫 도전으로 내세운 목표는 프로젝트 였습니다.
광고의 상품 특성 및 방향성을 고려해 해당 상품에 관심을 보일 확률이 높은 유저에게 광고를 노출시킴으로 써 광고주들의 광고가 ‘적절한’ 유저에게 전달되도록 하는 것이 가장 중요한 목표였습니다.
유저에게는 관심사 기반 광고를 제공해 보다 흥미로운 유저 경험을 선사하고, 광고주에게는 적은 예산으로 더 높은 KPI에 도달하는 고효율적 성과를 제공합니다.
나아가 이 프로젝트는 코르카에게 있어 방대한 데이터의 홍수 속에서 유의미한 정보를 추출해내고,

기업과 사회의 이를 활용해 AI Transformation에 기여하는 뜻깊은 도약이 되었습니다.
애드테크 프로젝트는 일반적인 머신러닝 프로젝트와 분명한 차별점을 지녔습니다.
- 초당 만 개씩 쌓이는 데이터
애드테크는 어떤 테크 분야보다도 압도적인 규모의 데이터를 다룹니다.
데이터 모바일, 웹 등 플랫폼을 사용하는 모든 유저 개개인의 총체적 행동이 곧 ‘ ’로 저장되는 곳이며, 그 총합 유의미한 패턴과 정보를 추출 속에서 해 낼 수 있어야만 성과를 도출할 수 있는 분야입니다.
코르카는 지금까지 다뤄보지 못했던 거대한 크기의 데이터를 다루기 위해 많은 고민을 했습니다.
트래픽 규모의 성장에 맞춰 확장이 가능한 머신러닝 모델 개발, 실시간으로 쏟아져 들어오는 데이터를 지연 없이 빠르게 처리할 수 있는 이벤트 스트리밍 플랫폼 개발, scale-out이 가능한 stateless 컴포넌트 개발 등 여러 고민들을 거쳤습니다.
- 24/7 돌아가는 서비스
24시간 내내 매초 수천 명에게 우리가 선정한 광고를 내보냅니다.
조금의 다운타임이라도 발생하게 되거나, 알고리즘에서 실수가 발견된다면 이는 곧 광고를 보여줄 수 있는 기회를 놓치는 상황을 초래하게 되며 금전적인 손해로 귀결됩니다.
애드테크라는 도메인의 이러한 특성상 다소 지겨울 정도로 많은 테스트가 필수적이었고 다운타임의 발생을 막으려는 수많은 노력이 있었습니다.
- 매일매일 격변하는 세상
우리는 ‘세상이 너무 빨리 변한다’라는 말을 종종 하곤 합니다. 그리고 애드테크 분야에선 실제 세상보다도 훨 씬 많은 것들이 빠르게 변합니다.
같은 사람이 오늘은 이 광고를 클릭했더라도 내일은 클릭하지 않을 수 있습니다.
클릭 확률이 좋던 광고가 어느 날 광고주의 사정으로 중단되며 성과가 하락할수도 있습니다.
유저들의 광고 선호도와 우리가 보유하고 있는 광고가 매일매일 빠르게 바뀝니다.
실시간으로 계속 학습을 진행하며 모델을 지속적으로 업데이트 즉 모델을 학습 한번하면 끝인 것이 아니라, 할 수 있는 구조 를 설계해야 했습니다.
정해진 예산 안에서 광고의 효율을 극대화하는 서비스 코르카에서는 이러한 조건들을 고려해 를 설계하였습 니다.
이 서비스는 바로 Bidding Engine for AdTech, BEAT입니다.
오늘 포스팅에서는 위 세 가지 특성을 모두 반영하는 BEAT의 아키텍처 설계를 위해 저희가 고민했던 것들을 공유하고자 합니다.
컴포넌트 설계 (광고의 효율을 측정하는 데는 여러가지 지표가 있지만 이 포스팅에서는 편의상 ‘클릭 수’만을 중점적 지표로 논의하도록 하겠습니다.)
- 클릭률을 예측하는 머신러닝 모델을 학습하는 컴포넌트
클릭률을 예측하는 머신러닝 모델을 학습하는 컴포넌트 클릭수를 극대화하기 위해선 제일 기본적으로 [1) ] 가 있어야 합니다.
‘어떤 유저’에게 ‘어떤 광고’를 ‘언제’ 보여주었을 때 ‘클릭률이 얼마’나 되는가?
정말 간단합니다.
- 예산을 24시간 동안 최적으로 소진하게 하는 제어 컴포넌트
클릭률을 아무리 잘 예측하더라도, 예산을 너무 과하게, 또는 적게 소진해서는 안 됩니다.
예산을 시간 최적의 방법은 24시간 동안 예산을 골고루 나눠서 알맞게 사용하는 것입니다. 이를 위해 [2) 24 동안 최적으로 소진하게 하는 제어 컴포넌트 ]가 필요합니다.
- 유저의 request가 왔을 때 광고를 적절한 가격에 경매를 하는 컴포넌트
유저의 가 왔을 때 광고를 위 컴포넌트들이 중요한 만큼, 실제로 이들을 ‘사용’하는 컴포넌트, 즉 [3) request 적절한 가격에 경매를 하는 컴포넌트 ]가 필요합니다.
번 컴포넌트인 머신러닝 모델 클릭률을 예측 번 컴포넌트인 제어 모델 적절한 경 1 을 추론하여 하고, 2 을 통해 매가를 구하는 것입니다.
개의 컴포넌트를 모두 병합 전부 이러한 흐름으로 생겨난 고민은, 3 하여 자원을 공유하는 것이 좋을지, 혹은 분리 하는 것이 좋을지에 대한 생각으로 이어졌습니다.
- 병합
장점: 프로세스 레벨 지연과 부하가 감소 모두 병합할 경우 컴포넌트 간의 통신이 이 되며, 유의미한 합니다.
호환성 문제가 발생하지 않습니다
모두 하나의 서비스로 배포가 되기 때문에 .
단점: 3번 컴포넌트 한 개만 변경되더라도 나머지 1, 2번 컴포넌트까지 같이 build, test, deploy 과정을 다시 거 쳐야 합니다.

부분 장애가 전체 서비스의 장애로 확대될 가능성이 커집니다.
- 분리
장점: 장애가 격리 안정적 되고 보다 입니다.
개별적으로 배포 가능 3개의 컴포넌트를 하기 때문에, 3번 컴포넌트는 유지하고 1, 2번 컴포넌트만 쉽게 변경 가능합니다.
단점: 네트워크 레벨 컴포넌트 간의 통신을 에서 처리해야 하므로 개발해야 할 것이 많아지고 지연과 부하가 발 생합니다.
컴포넌트 간의 호환성을 꼼꼼히 확인해야 합니다.
의 장단점 이는 전형적인 monolithic architecture vs microservice architecture 입니다.
분리 즉 코르카는 개발양이 많아지고 배포 과정이 복잡해지더라도, 용이한 컴포넌트 변경을 위해 후자인 , microservice architecture를 선택하게 되었습니다.
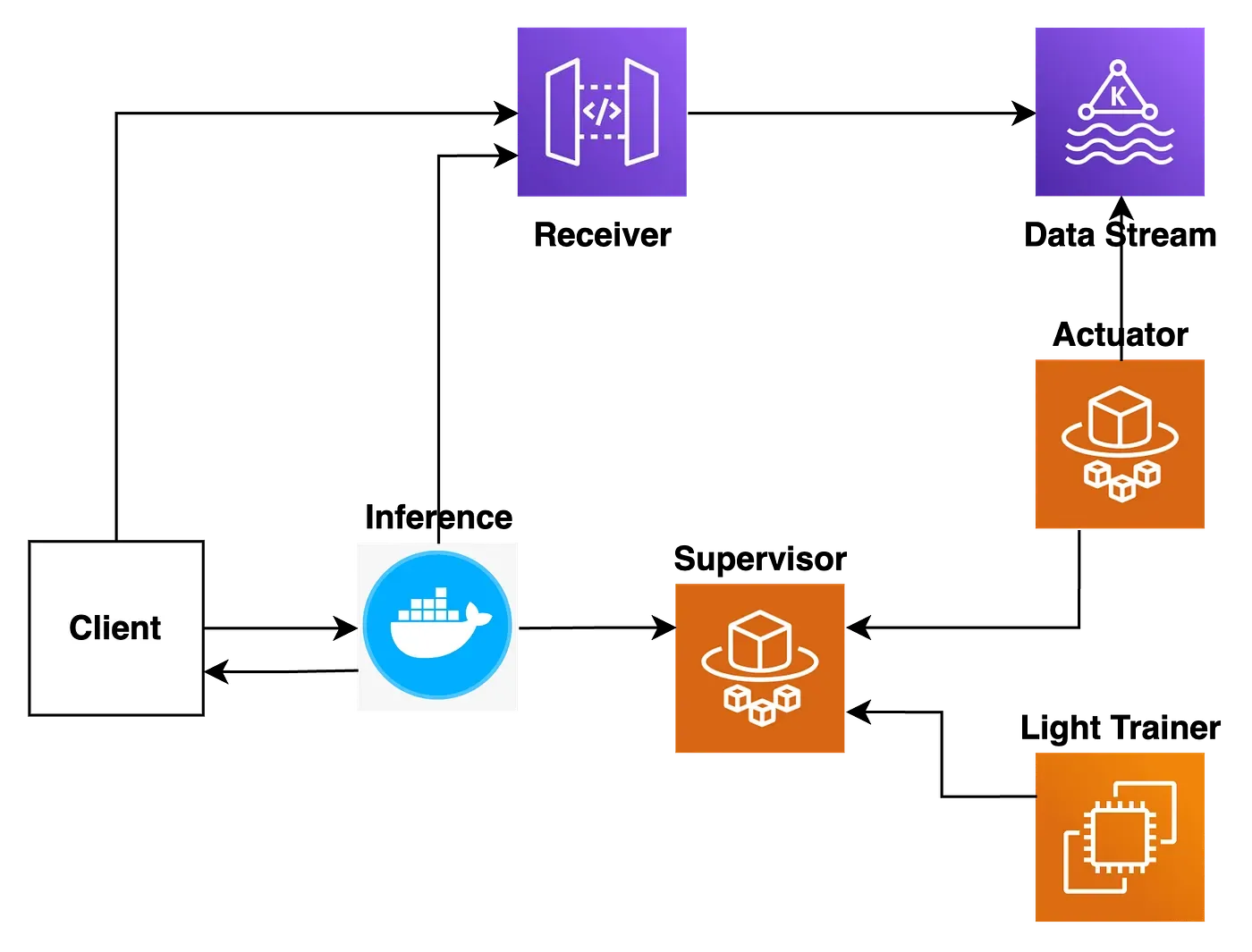
1번 컴포넌트는 머신러닝 모델을 빠르고 가볍게 학습하는 Light Trainer, 2번 컴포넌트는 예산을 최적으로 소진할 수 있게 상시 제어하는 Actuator, 3번 컴포넌트는 실시간으로 지속적인 추론을 하는 Inference라고 부릅니다.
를 에 전달 Light Trainer는 머신러닝 모델을 학습한 checkpoint Inference 할 것이고, Actuator는 예산을 최적 를 실시간으로 계속 에 전달 으로 소진하기 위해 지금 가져야 하는 state update하여 Inference 할 것입니다.
이제 경매를 하기 위한 기본적인 준비는 모두 마쳤습니다.
이제 Light Trainer와 Actuator에 적절한 데이터를 넣어줄 수 있도록 데이터 파이프라인을 구축하면 됩니다.
데이터의 실시간성 유무 매일 변하는 세상에 적응하기 위한 학습 방법
이 때 고민해야 할 것은 2가지: 와 입니 다.
- 데이터의 실시간성 유무
초단위의 실시간 정보가 크게 영 A. Light Trainer는 클릭률을 정확히 예측하는 역할을 하며, 이 태스크에는 향을 미치지 않습니다
.
그렇다면 batch data를 사용하면 되고 이는 AWS의 S3를 통해 데이터를 다운받아서 학습을 진행할 수 있 습니다.
B. Actuator는 예산을 24시간 동안 나눠서 적절히 소진해야 하는데 최근 10초, 1분 동안 엄청나게 많은 예산 을 사용했다면 바로 예산 사용률을 줄여야 합니다.
그렇기에 이 Actuator는 stream data를 필요로 합니다. 이 stream data를 처리하기 위해서는 [4) stream 를 외부로부터 받는 컴포넌트 data ]가 필요합니다.
그리고 이 데이터를 굉장히 효율적으로 처리해야 합니다. 이 프로젝트의 첫번째 특징인 “초당 만개씩 쌓 이는 데이터” 때문입니다. 데이터가 너무 많기 때문에 이 데이터를 바로 Actuator에게 전달하면 Actuator 가 부하를 감당하지 못할 위험이 상당히 큽니다. 그렇기에 중간에 이 데이터를 가공하는 부분이 반드시 를 하는 컴포넌트 필요합니다. 즉, [5) stream data real time processing ]를 개발하게 됩니다.
번컴포넌트 4 는 데이터를 받기에 Receiver, 번컴포넌트 5 는 데이터가 흘러가는 곳이므로 Data Stream이라고 부릅니다.
- 매일 변하는 세상에 적응하기 위한 학습 방법
매일매일 격변하는 세상 에 적응하는 방법을 고민 마지막으로 이 프로젝트의 세번째 특징인 ‘ ’ 해봐야 합니다.
‘매일 바뀌는 세상’에 적응하기 위해서는 ‘매일 학습’하는 것이 당연한 해결 방법일 것입니다.
시간마다한번씩학습 체크포인트를 에전달 따라서 Light Trainer는 1 하고 Inference 해야 하며, Actuator는 10 초에한번씩업데이트된 를 에전달 state Inference 합니다.
는 클라이언트의 모든 에 대응되어야 하므로 여기에서 한가지 문제가 있습니다: Inference request scale-out 이 일어날 수 있습니다
.
그렇게 scale-out이 일어났을 때, Actuator와 Light Trainer는 새롭게 배포된 Inference 인스턴스를 찾아 내고 state 및 checkpoint를 전달할 수 있을까요?
혹은 scale-in이 일어나서 더 이상 전달이 필요 없다면요?
이를 Actuator와 Light Trainer 안에서도 진행할 수 있겠지만, 이는 Actuator와 Light Trainer 컴포넌트가 각 자 맡은 역할과 상충합니다.
를 추론부에 전달하기 위한 컴포넌트 이를 막고자 [6) state, checkpoint ]를 개발하였습니다.
컴포넌트 응집도는 더욱 상승 컴포넌트별 배포는 더 쉬워졌습니다
이를 따로 개발함으로써 했고 .
6번 컴포넌트는 중간에서 모든 것을 관리하기에 감독관, 즉 Supervisor라고 부릅니다.
여기까지 코르카의 BEAT 아키텍처에 대한 기본적인 설명이었습니다.
이를 그림으로 나타낸 모습은 아래와 같습니다.
지금까지 다뤘던 내용을 다시 정리해보겠습니다.
- 컴포넌트 응집도를 높이기 위한 아키텍처 설계
- 컴포넌트별 설명 (Light Trainer, Actuator, Inference, Receiver, Data Stream, Supervisor)
오늘의 글에서 기초적인 아키텍처 설계에 대해서 다뤘습니다.
다음 글에서는 더욱 저희의 니즈에 맞는 아키텍처를 설계할 수 있도록 고민한 측면에 대해 자세히 다룰 예정 입니다.
우리가 살아가는 세상을 AI 기술로 변화시키는 팀 Corca는 고도화된 기술력과 기획력을 토대로 새로운 가치 를 창출하고 있습니다.
Corca의 여정에 함께하실 분들은 코르카 채용페이지를 확인해주세요!
기술 발전의 혜택을 모두가 누리게 하여 인류 문명의 발전에 기여하는 코르카