Corca Medium 아카이브
Auto? Scaling. 직접 구현한 Scaling
코디 추천 서비스인 🚀 코르카가 6월 1일에 AI Closet을 런칭했습니다
무엇이 우리의 상황에 더 맞는지 고민하고 짧은 기간 안에 빠르게 런칭한 만큼 개발에 있어 많은 선택지들 중 결정 했던 것들이 정말 많았습니다.
이번 글에서는 그렇게 고민했던 주제들 중 하나인 Auto Scaling 정책을 그대로 사용해도 되는 것인지에 대해 다뤄보려고 합니다.
(모든 조건에 대해 정확하게 여러 번 측정한 게 아니니 재미로만 봐주세요!)

Auto Scaling이란?
사용자가 정의한 정책에 따라 Auto Scaling은 AWS 좀 해보셨다 하는 분들은 다들 들어보셨을 텐데요, CPU 등의 이 어느 구간에 있는지 파악하여 자동으로 작업 Utilization Metric Scaling 을 해주는 AWS 서비스입니 컴퓨팅 자원을 조절 주로 의 다. 여기서 말하는 Scale이란 하는 것을 말하는데요, CPU, Memory, EC2 instance 개수 등이 이에 해당됩니다.
Scaling의 종류로는 Scale In, Out, Down, Up이 있는데
- Scale In, Out은 자원의 개수를 늘리거나 줄이는 것이고,
- Scale Down, Up은 자원의 크기를 키우거나 줄이는 행위를 말합니다.
예를 들면 CPU를 2vCPU에서 4vCPU로 늘리는 행위는 Scale Up이고, EC2 Instance의 개수를 3개에서 2개로 줄이는 행위는 Scale In이겠죠.
Closet을 CPU, Memory metric을 일정 범위 안에 들어오도록 하는 정책(target-tracking scaling policy)을 이 용해서 배포하다가 Scale Out 시간이 3분을 넘어가는 부분을 개선하고 싶었습니다. 결론을 짧게 먼저 말씀드 리면 고민화는 과정에서 많은 것을 알 수 있었지만, Scaling을 직접 구현하는 것 외에 Closet에 적용할 수 있는 😢 방법은 떠오르지 않았습니다
Terminology
그럼 Auto Scaling을 이해하기 위해 필요한 몇 가지 용어들을 살펴보겠습니다!
- AWS EC2
Elastic Compute Cloud의 줄임말이며, 가상의 컴퓨터(Instance)를 클라우드상에서 실행할 수 있게 합니다.
Instance state에는 Running, Stopped, Hibernated, Terminated가 있는데, Stopped는 말 그대로 정지된 상태이며 다시 켤 수 있습니다.
Terminated는 Instance 자원을 반납하여 다시 켤 수 없습니다. Instance가 더 이상 필요없을 때 사용자는 terminate 요청을 보내게 됩니다.
Hibernate는 절전 모드와 비슷한 개념인데, RAM의 데이터를 하드 디스크에 저장해서 나중에 다시 Running 상태가 되면 실행하던 프로그램을 그대로 실행할 수 있으며, 그 외에는 Stopped 상태와 동일합 니다.
- AWS ECS
Elastic Container Service의 줄임말이며, Docker Container를 클라우드상에서 배포할 수 있습니다.
Cluster는 Service의 집합, Service는 Task의 집합이며, Task에서는 Container가 어떻게 동작할 지 정의할 수 있습니다. (Image URL, Container에 할당될 CPU나 Memory 등등) Task 배포 종류로는 Fargate, EC2, External이 있는데, 그 중에서 Fargate는 서버리스 형태로 컨테이너 호스트를 신경 안써도 되게 동작합니다. (서버리스라서 EC2와 다르
게 Image cache가 불가능합니다.)
EC2는 EC2 Instance 안에서 task가 동작하며, 이때 Instance 안에는 ECS-agent라는 프로그램이 작동합니 다.
EC2 Instance boot → ECS-agent / Cluster 연결 → Run task → ECS-agent가 task definition을 전달받아서 컨테이너 실행합니다.
서버리스인 Fargate와는 다르게 호스트 Instance 안에 동일한 Image를 사용하는 Container가 있으면 cache로 사용 가능합니다.
- AWS Cloudwatch
Cloudwatch에서는 AWS의 서비스들로부터 다양한 metric을 수집할 수 있고, metric의 범위에 따른 action을 실행할 수 있습니다.
ex) EC2의 특정 Instance의 CPU Utilizaiton이 높아지면 AWS SNS라는 곳으로 알림을 보내서 사용자가 이 메일 또는 slack 등으로 알림을 받을 수 있습니다.
Action에는 Auto Scaling group의 Scale In, Out도 포함됩니다.
EC2 Instance를 grouping해서 Cloudwatch로부터 알림을 받아 필요에 따라 scale in, out할 수 있습니다.
warm pool을 설정하여 scale out에 대비하여 Instance를 미리 running, stopped, hibernated 셋 중 하나의 state로 준비시켜둘 수 있습니다.
차가운 데워놓은 원래는 (cold) Instance를 사용하지만 미리 (warm) Instance를 사용한다면 scaling 시간 을 절약할 수 있습니다.
Closet은 현재 ECS의 Fargate 형태로 배포되고 있는데요, Fargate는 EC2 배포형태보다 조금 더 비쌉니다. 그 의 가장 큰 단점은 가 불가능하여 가 상태가 될 때까지 항상 시간만큼 더 소요
pulling 된다는 것입니다.
미리 을 해놓은 를 로 대기시켜서 로 배포하는 이 단점을 극복하기 위해 Image pull Instance warm pool EC2 건 어떨까 ? 하는 생각이 들었고, Instance가 Stopped, Hibernated 상태에서 Running 상태로 돌아오기까지 얼마나 시간이 걸리는 지 알아보기 시작했습니다. 만약 Image pulling time보다 짧다면 비용 측면에서나, 배 포 시간 측면에서나 나쁘지 않은 선택이 될테니까요!
Conditions
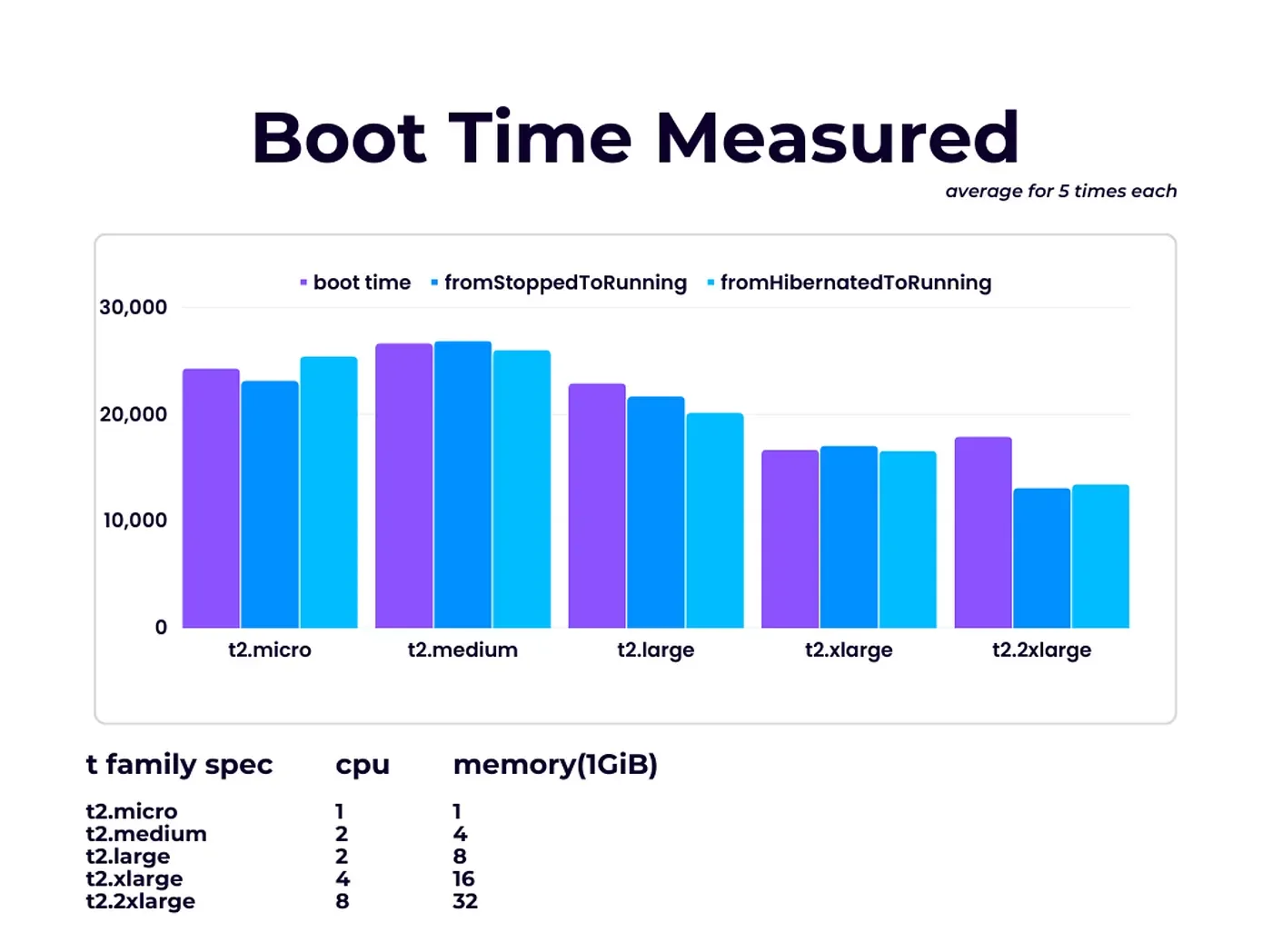
EC2 Instance boot time을 측정했습니다.
단위는 millisecond입니다!
Instance type들 중 t2 family(General Purpose Types)에 대해 측정을 5번씩 진행했습니다. (t2.2xlarge만 3번)
Launch Instance → Running → Stopped → Running → Hibernated → Running → Terminate의 순서로 Instance state를 바꿨으며, 아래 총 3개 구간의 시간을 측정했습니다.
- Stopped → Running
- Hibernated → Running
Results
Insights
은 과큰차이가없었습니다
생각보다 fromHibernatedToRunning boot time .
부팅 프로그램 실행 시간이 매우 짧다
자원 할당 / 준비 기간이 대부분이고, 는 뜻입니다. (실제로 로그를 체크 해본 결과 보통 5초 안쪽이었습니다.)
프로그램 실행하는 거 없이 단순히 부팅까지의 시간을 측정했기 때문이기도 하죠!
게임 서버같이 실행이 몇 분 몇 십분 단위로 걸리는 프로그램 시키 ~ 을 실행해야 하는 상황이라면 Hibernate 는 것이 더욱 효과적 일 것입니다.
도 과큰차이가없었습니다
Launch Instance와 Start Instance(Stopped → Running)는 EBS volume(EC2의 저장장치 중 하나)을 새로 만 드는 것 말고는 본질적으로 같은 게 아닐까 하는 생각이 들었습니다.
사람들이잘안쓰는 이라서사용 Instance 스펙이 좋아질 수록 대체로 부팅 시간이 빨라지는데, Instance type 자에게자원을할당하는것이빠른것같습니다
.
제가 추측해 본 이유인데, 클라우드 서비스 업체에서 컴퓨팅 자원을 어떤 방식으로 할당하는지 몰라서 확실 😢 하지는 않네요
Boot Time measure의 결과가 생각과 달랐는데요, 그래도 대략 30초 안에 Instance를 Running 상태로 만들 수 있다는 걸 알았습니다.
그럼 이제부터 task를 실행하는 데에 걸리는 시간을 알아보도록 하겠습니다!
Conditions
runTask api 호출하고 task status가 running 상태가 될 때까지의 시간을 측정했습니다. (각각 2~3번 측정한 것들의 평균을 구했습니다.)
- Fargate task 실행
- warm Instance는 warm pool의 stopped Instance에서 task 실행
3, 4번은 ECS에 Auto Scaling을 연결해 놓으면 (정확히는 capacity provider입니다!) runTask api가 호출 되면 알아서 Instance를 시작시켜 그 안에서 task를 실행해 줍니다.
EC2 Instance type은 t2.medium (2vCPUs, 4GiB Memory)을 사용했습니다.

1GB 이미지 크기를 사용하였습니다.
Image pulling 시간은 대략 30초입니다.
# /var/log/ecs/ecs-agent.log ...
...
Results
Fargate: 42s
EC2
- Hot Instanc
non-cached: 58s cached: 19s
- Warm Instance
non-cached: 198s
Insights
hot instance라고 가정하면 값도 싸고, 캐싱도 가능해서 단기적으로는 Fargate보다 EC2가 이득입니다.
비용과, 배포 시간 측면 모두를 고려했을 때도 말이죠!
warm instance with cached가 fargate보다 빠를 줄 알았으나 예상보다 너무 느렸습니다.
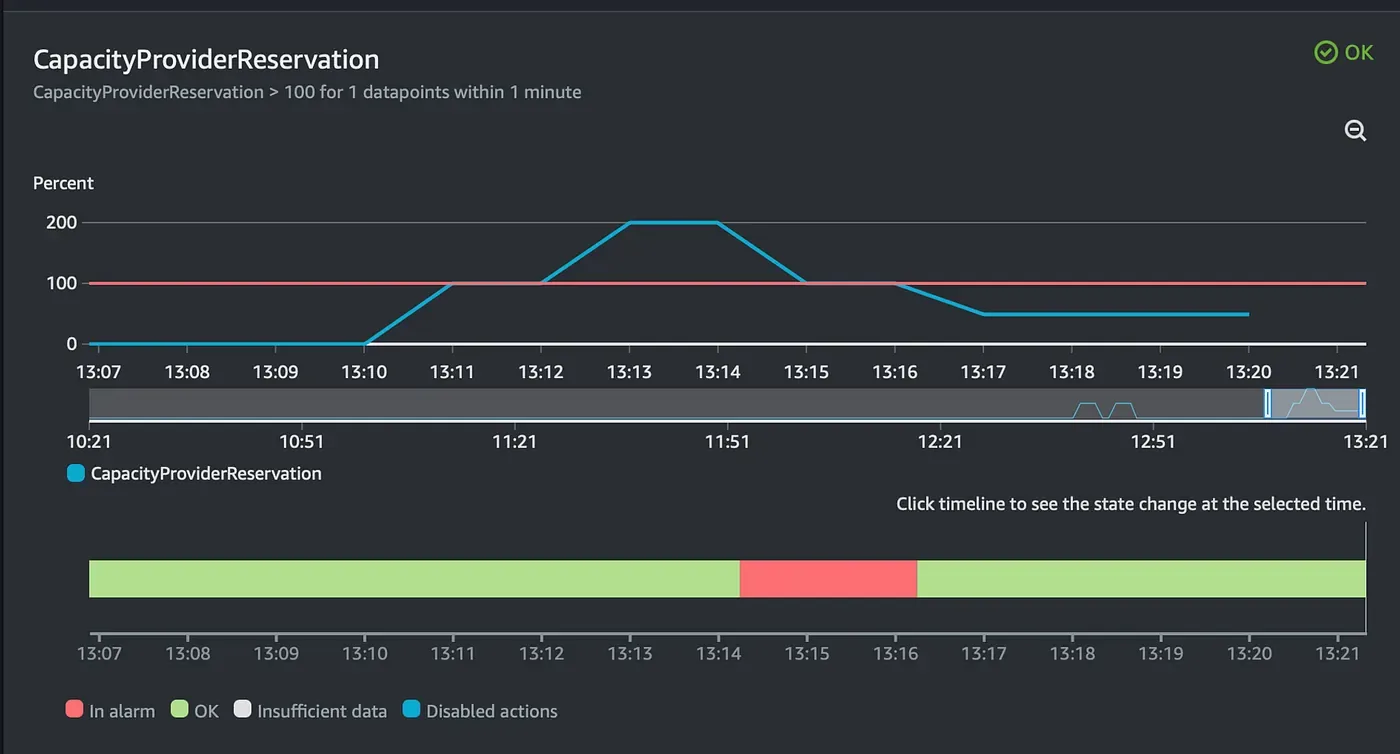
Cloudwatch metric alarm이 너무 늦게 울렸기 때문입니다!
warm instance with cached의 경우를 실제로 실험하지는 않았지만, 이미지 풀링에 30초가 걸리는 것 말고는 warm instance with non-cached와 동일할 것이기 때문에 해당 데이터를 바탕으로 분석해 보았습니다.
- 12분 47초에 runTask api 호출
- 14분 45초에 알람 울려서 auto scaling group에서 scale out을 시작
ecs-agent가 14분 46초에 시작한 것으로 보아 stopped상태에서 restart할 때 바로 ecs-agent가 실행됐네 요. 대략 30초 후에 task를 전달받으므로 ec2 boot time measure의 결과(30초)와 어느 정도 맞아떨어지는 걸 볼 수 있습니다.
# /var/log/ecs/ecs-init.log ...
...
- 15분 16초에 instance가 running 상태가 되고, ecs-agent가 runTask 명령을 전달받습니다.
아래 로그는 ecs-agent가 task를 실행할 때 제일 처음 하는 일인 eni attach할 때의 로그입니다.
# /var/log/ecs/ecs-agent.log ...
...
- 16분 6초에 task running
metric을 사용자가 계산해서 scaling을 한다면, 즉 직접 scaling을 한다면 fargate와 비슷한 배포 시간으 로 저렴한 가격에 서버 배포 가능할 것 같습니다. 특히 이미지가 커질 수록 풀링 시간이 길어져서 fargate 보다 더 빨라질 수 있습니다!
Summary
Cloudwatch metric으로 scaling을 하는 것은 1~2분 정도 latency가 존재합니다.
특히 ECS capacity provider는 metric check period를 설정하는 게 불가능하기 때문에 매우 느립니다(2분).
10초 단위로 급하게 트래픽이 몰릴 일이 잘 없고, bootstrap time이 길고, 이미지 크기가 큰 서비스가 hibernated warm pool을 사용한다면 최대의 효율을 뽑을 수 있을 것 같네요!
이미지 크기를 줄이는 그러나 Closet은 그런 서비스가 아니기 때문에 현재로서는 scaling을 직접 하거나 게 최선이라고 결론이 났습니다
.
ECS-agent의 로그를 살펴보며 새롭게 알아낸 것들을 공유합니다!
니다.
(이때 만들어진 connection으로 task를 전달받고, status check 등을 합니다.)
Container를 실행하면 ENI attachment 작업을 제일 처음 합니다 (네트워크 카드를 붙이는 작업) 컨테이너가 최소한의 네트워크 작업을 수행하기 위한 private ip address 할당인 듯 하네요!
task 설정 중 public ip assigned = true면 이때 붙인 eni에 public ip 할당도 같이 합니다.
지금까지 Auto Scaling에 관하여 얘기를 했는데요, 고민을 많이 했지만 지금 구조에서 크게 바꿀 수 있는 건 🥲 없어 보여 많이 아쉬웠습니다 그래도 개인적으로는 ECS와 EC2, Auto Scaling, Cloudwatch의 유기적인 동 작에 대해 알게 되어서 그간 애매하게 알고 있었던 지식들을 정리하는 시간을 가질 수 있어 좋았습니다. 다음 에는 더 재미있는 주제로 돌아오겠습니다!
Reference
https://github.com/rudxor02/fargate-vs-ec2
우리가 살아가는 세상을 AI 기술로 변화시키는 팀 Corca는 고도화된 기술력과 기획력을 토대로 새로운 가치 를 창출하고 있습니다.
Corca의 여정에 함께하실 분들은 코르카 채용페이지를 확인해주세요!
기술 발전의 혜택을 모두가 누리게 하여 인류 문명의 발전에 기여하는 코르카